

It’s odd to realize how Artificial Intelligence (AI) and unstructured data are so commonplace in every organization, yet the two they often don’t come hand in hand.
If you take a closer peek into top AI applications in the enterprise—like big data analytics, digital trade, and machine learning—one big similarity is the use of structured data. But it’s not always that we get clean sets of data, arranged in giant excel sheets for us to use.
In fact, structured data is actually a minority. On the contrary, about 80% of data isunstructured data.
What is the main difference between structured and unstructured data?
Structured data are kinds of data that can fit into traditional column-row databases or spreadsheets. Semi-structured and unstructured data are pretty much everything else.
Table of Contents
Examples of semi-structured and unstructured data
- Emails
- Notes and minutes
- Contracts
- Financial statements
- Invoices
- Resumes
- Images and audio
- Social media posts
The list goes on!
Characteristics of unstructured data
Unstructured data are data points that are heavily clouded with noise and randomness. This makes such data impossible to stuff into a neat spreadsheet.
Think of noise as additional ‘data’ that you aren’t interested in. Such noise often comes as free flowing text, descriptors and also line items for documents with tables. For example, a lengthy financial statement may contain comprehensive information on cash flows—i.e. noise—when all you’re interested in is the net income data point.
Randomness is where your data points aren’t consistently located across different information sources. A similar financial report from two distinct companies could display the data in various ways. Just like how resume written by two candidates will never be identical. In the real world, most documents face high variability that can be characterized as unstructured.
How are AI and data linked?
Despite the differences between structured and unstructured data, how AI uses data is similar.
Data is a foundational element of AI. Models powered with AI first use training data as input to learn how to make generalizations, and are then applied on similar types of data.
For example, a machine learning model trained on a massive data set of customer purchase behaviours—like quantities purchased, demographic breakdown and purchase platform—can predict how customers might behave in the future. This can enable retail companies to optimize inventory and Omni-channel marketing tactics, or even predict what new products to roll out.
So why do most AI tools struggle to read unstructured data?
We take for granted how easy it is to read data like in the financial report we shared earlier. Unlike humans, machines face extreme difficulty doing so.
The issue is specificity.
AI models learn from the past, to make better decisions about the future. As such, models are only as good as the data they are trained with. Train a computer vision model with images of cars, and it becomes great at differentiating a car from a pedestrian.

In a structured world, there’s high domain specificity—i.e. cars vs pedestrians. It is clear what training data is needed to build a model, and it is clear what potential applications the model has. That computer vision model can then contribute to developing self-driving vehicles.
But with semi-structured and unstructured data, domain specificity is lost.
Noise and randomness confuse machines when they’re trying to make generalizations between a training data set and the real world. That’s because we can no longer confine the data set to belong to a specific domain.
How should AI move forward to better manipulate unstructured data?
Fortunately, certain AI technologies can effectively exploit unstructured data, by adding ‘human intelligence’.
Instead of just inductively examining sets of data to create generalizations, AI tools that perform best with unstructured data must also deductively analyze data based on pre-taught logic and rules.
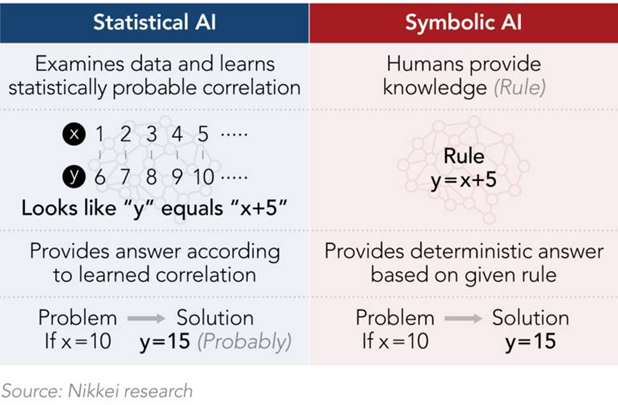
These two inductive and deductive thought processes are statistical and symbolic AI.
Our previous examples shed light on statistical AI, which is more commonly used in the enterprise to handle big data.
However, particularly with unstructured data like language, symbolic AI plays a critical role. Using logic and reasoning within domain-specific semantics, symbolic AI models have ‘human knowledge’ to better read unstructured data, akin to human’s abilities.
The best AI tools need to use ‘hybrid’ AI
For enterprises and digital organizations, taking a ‘hybrid’ approach in AI adoption will be the critical competitive advantage to apply AI at scale.
The most powerful AI tools that can tap into our vast pool of unstructured data will blend the strengths of various AI systems from both disciplines.
- Statistical AI—such as Machine Learning, Deep Learning, Probabilistic Learning
- Symbolic AI—such as Natural Language Processing, Reasoning, Knowledge Representation and Graphs, Planning
Such a hybrid AI approach is part of AI company TAIGER’s offering. With a combination of statistical and symbolic AI, the Singapore-based company delivers intelligent document processing, enterprise search and conversational AI tools specialized at manipulating unstructured data.
For example, TAIGER’s intelligent document processing tool, Omnitive Extract, uses both Machine Learning and symbolic AI driven techniques like Natural Language Processing and Ontology. This way, the tool can read a wide range of unstructured document types even if the AI model has not been exposed to similar documents during training. With symbolic AI, the model already understands linguistics and semantics, enabling it to read documents with humanlike intelligence.
AI will evolve to tap into our unstructured world
AI is going to change the way we work in the future—but shouldn’t be limited to a structured utopia. With the right blend of tools, AI can unlock new opportunities to make work easier and faster like never before in our unstructured world.



